初出:2007年09月24日
いよいよ、デュアルコアで小惑星への探査軌道の計算をやってみた。
この辺から、ダウンロードした 603個(2月に計算した時は 430個だった)の小惑星の軌道要素から、計算する。
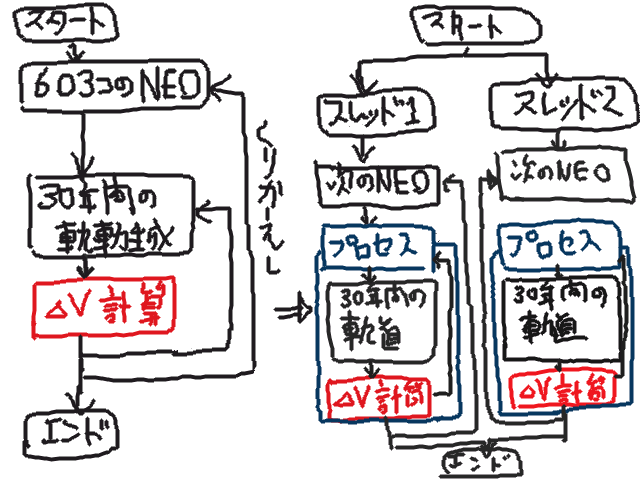
元々のプログラムは、シングルコア用で、図の左のようなフローになっている。
603個のNEO毎に、30年間を10日毎に軌道計算して位置を求め、その往復に必要なΔVを計算している。
図の中で、赤線で書いた部分が非常に計算量が多く、フォートランのプログラムをコンパイルしている。
黒線の部分は、意外と計算量が少ないが、プログラムを頻繁に変更するので、Ruby で処理している。Ruby の部分は、当然インタープリタだ。
Rubyのメインルーチンから、フォートランをサブルーチンとして呼び出しているような構造になっているわけだ。サブルーチン代わりと言え、当然、プログラムの呼び出しだから、別プロセスを起動している。
システムモニターを見ながら、左側のプログラムを走らせたところ、2つのCPUコアが50%強程度で動いていた。これは、各コアに、Rubyとフォートランのプロセスが割り当てられたのではなく、大量に発生するフォートランプログラムのプロセスが、その度毎に違うコアに割り当てられたからだと思われる。
さて、デュアルコア用にプログラムを変更したのが、図の右側である。
比較的複雑な構造になっているのは理由がある。
当初、603個のNEOを半分にして、302個を一つのコア、残り301個のNEOをもう一つのコアに割り当てて、二つのプロセスを起動すれば良いと思っていた。しかし、上手く行かない。
603個のNEOを計算しても、全てのNEOを同等に軌道計算しているわけではない。
有人探査を目的としているので、往復に1年半以上必要な小惑星は計算していないのだ。
小惑星の軌道は、地球に近いからと行って、必ずしも短時間で往復できるわけではない。
地球と小惑星の位置の関係から、近い軌道でも、往復しやすいタイミングは限られている。
(何十年ぶりの火星の大接近とか言うでしょ)
だから、計算対象の30年間で、そもそも、往路に1年半以上かかるNEOは復路計算は行っていない。
往復両方計算している小惑星はむしろ少数派だ。
603個のNEOの内、1年半で往復できると判断できたのは、105個だけだ。
これら105個のNEOに関しては、繰り返し繰り返し計算されている。
いきなり603個のNEOを計算するのは大変なので、最初、10個とか20個から始めた。
最初の10個には、105個のNEOは一つも含まれていなかった。ところが、11個目から20個目には、2個の有望なNEOが入っていたのだ。
20個のNEOを計算試験では、最初のプログラムは、一つのコアに最初の10個、もう一つのコアに11個目から20個目を割り当てた。
システムモニターを見ながら走らせたのだが、プログラムの問題は明らかだった。
最初のコアは、すぐに計算が終わったのだが、もう一つのコアは何時までも終わらない。
結局、シングルコア用のプログラムから、ほとんど改善されていない。
今回、少数だったので、たまたま小惑星が偏っただけかも知れない。小惑星の総数が増えたら、もっと均一に分散するかもしれない。だが、ランダムな分散と仮定しても、必ずしも二つに分けたときに偏りが減るわけでない。また、計算しなければ、有望かどうかわからないので、予め計算が均一になるように分けることもできない。
そこで、プログラムを分け、2つのスレッドを走らせた。この2つのスレッドは Ruby 1.8 なので、本当のスレッドではなく、エミュレーションのようなものだ。スレッド間ではメモリーを共有できるので、603個の小惑星の何処まで計算したか判る。
2つのスレッドは、それぞれ、小惑星を一つだけ計算する別プロセスを起動する。起動されたプロセスは、それぞれ別のコアに割り当てられる。プロセスが終了すると、次の小惑星が割り当てられる。これによって、一つのコアに処理が集中することを避けた。
計算結果は、次のようになった。
小惑星30個の計算:
・モバイルセレロン 450MHz Linux sarge 686 2時間38分38秒=9518秒 (シングルコア用プログラム)
・Athlon64 X2 4200+ Linux etch 686(32ビット版) 12分46秒=766秒 (デュアルコア用プログラム)
・Athlon64 X2 4200+ Linux etch amd64(64ビット版) 14分52秒=892秒 (デュアル用プログラム)
意外な事に、32ビット版の方が16%も速い。
普通、64ビットの方が、「アクセスできるメモリー容量が大きい」とか「汎用レジスタが8個から、16個に増えている」とかで、シミュレーションなどの計算には向いていると言われている。今回、前者のメモリー容量は関係ないが、レジスタ数で64ビットの方が有利かと思っていたが、結果は逆だった。
64ビットの方が、プログラム容量が増えるとか、各変数のビット数が増えて、オーバーヘッドなどで不利になるのかも知れない。
最後に、603個のNEO全てを計算した。もちろん、担当するのは、32ビット版だ。
・Athlon64 X2 4200+ Linux etch 686(32ビット版) 3時間18分54秒=11934秒 小惑星603個
うーん、速い。ちなみに、同時に Webや動画を見ても、全くストレスが無い。
モバイルセレロンの12倍だ。前の試験よりも差が開いたのは、メモリー容量の差だと思う。小惑星のデータはかなり大量だが、モバイルセレロンのPCには、192MB のメモリしか載っていない。片や、Athlon64 X2 の方は 1GBだ。
仮に比例関係が成立すると、モバイルセレロンなら、41時間11分27秒もかかることになる。(いや、2月に計算した時は、実際、そのくらいかかったし。あの時は430個だったけど)
デュアルコアは、やはり速いのう。
私のやり方は、少し特殊なケースなのかも知れない。
流体シミュレーションのように、もっと密接に結びつく場合には、今回のようなやり方は通用しないだろう。
だが、私の経験では、こう言ったやり方に当てはまる大量計算も、それなりにあると思う。
何かの参考になれば、幸いだ。
注意
ブログのコンテンツの内、「告知」など時期よって情報価値が無くなるのは除いてある。また、コンテンツに付いたコメントは書き込み者に著作権があるものと判断し、ここに持ってきていないので、コメントを見るときは、元々のブログコンテンツを参照してもらいたい。
その他、ブログ発表後、コメントなどの内容を反映するなど、内容を変更しているものもあるので、注意してほしい。